Did the Gemma 4 dense model actually regress? Last week, a significant divergence was highlighted between the Mixture-of-Experts (MoE) and dense architectures of Gemma 4. The narrative, fueled by a specific scenario involving a customer looking for white shirts, suggested the dense model was outright refusing valid queries, while its MoE counterpart performed admirably. This was chalked up to architectural differences.
Here’s the thing: that entire narrative was, to put it mildly, incomplete. The true culprit wasn’t some deep-seated architectural flaw. It was a simple, low max_tokens setting. A cap that was, effectively, starving the model’s reasoning process before it could even finish formulating a response.
The Case of the Stubborn White Shirts
Let’s rewind. The original experiment involved running Gemma 4 26B MoE and Gemma 4 31B Dense through an Arabic e-commerce chat router. The constraints were tight: an Arabic-first system prompt, a temperature capped at a chilly 0.3, and critically, a max_tokens limit set at a mere 400. Under these conditions, the MoE model shifted from stalling to providing grounded answers, while the dense model, perplexing everyone, began throwing false-negative refusals, including on that infamous white shirt scenario where the product was clearly within its context window.
The original article, and frankly, my initial analysis, leaned heavily into the architectural divergence. It felt like a neat, albeit inconvenient, explanation. MoE versus Dense, a classic showdown.
Enter the Crowd (and Common Sense)
But the internet, in its infinite wisdom, rarely lets a flawed premise stand unchallenged. The comment thread, spearheaded by Robin Converse on her sovereign Ollama stack, offered a compelling alternative. What if the problem wasn’t the architecture itself, but the constraints I was imposing on it? Converse proposed a hypothesis: the max_tokens: 400 cap was effectively muzzling Gemma’s reasoning layer. It wasn’t that the model couldn’t answer; it was that it wasn’t being allowed enough digital ink to formulate its answer before the system cut it off.
This is where it gets interesting. This wasn’t just a vague suggestion; Converse provided concrete data. She ran her own tests, uncapped, on her own setup, using the same scenarios. Her MoE handled everything correctly, and when she replicated the capped tests on her end, she saw the same refusal patterns. The suggestion was clear: the divergence was largely an artifact of the budget. A budget that was too small.
The comment thread reframed it. Robin Converse (Triava Labs, running the same model family on self-hosted Ollama) ran her own uncapped sweep on her sovereign stack — same scenarios, three temperatures,
max_tokensunrestricted.
This kind of collaborative debugging, the willingness to say ‘I might be wrong, let’s test this,’ is the absolute bedrock of progress in this field. It’s not about PR wins; it’s about finding what actually works.
The Single-Variable Test: Budget Boost
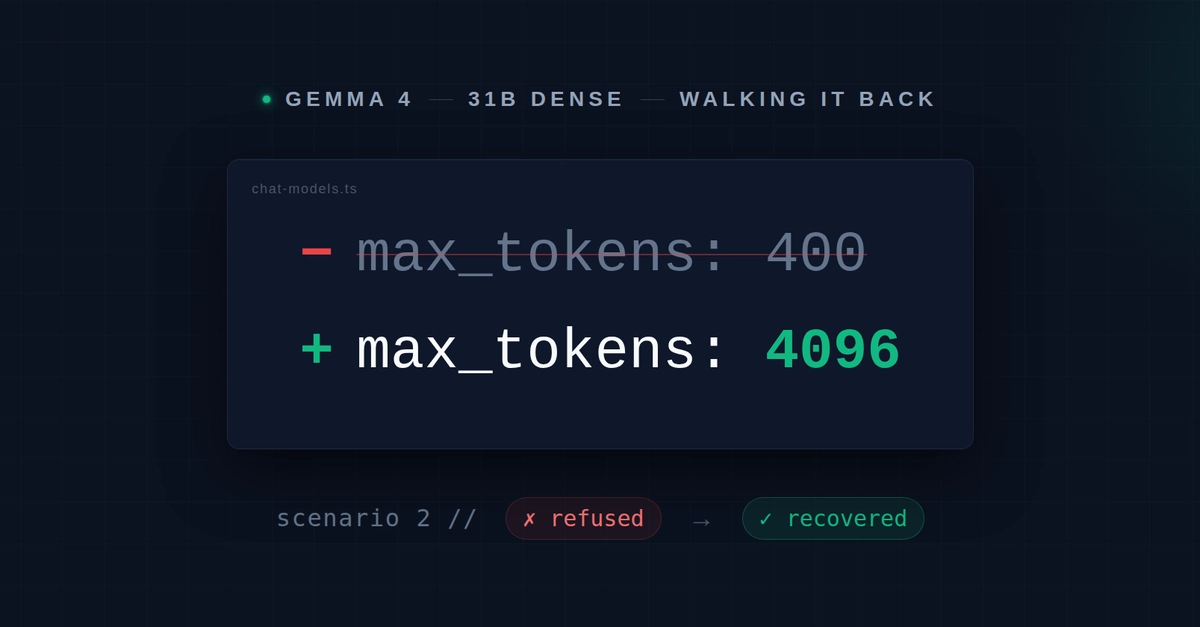
The hypothesis was simple enough to test: If the cap was the issue, raising it should resolve the discrepancies. So, I re-ran the exact same six scenarios, on the exact same two architectures, with the sole variable being the max_tokens limit, increased from 400 to a generous 4096. No prompt changes, no router adjustments, no new model rules. Just more room to breathe.
The results? Undeniable. Both the 26B MoE and the 31B Dense models recovered on every single scenario. That headline-grabbing false-refusal? Gone. The divergence that seemed so architecturally significant? Largely evaporated. The dense model, given adequate space, performed exactly as one would expect. The MoE model continued its strong performance. The cap was indeed doing the heavy lifting – the heavy negative lifting, that is.
The Real Story: Orchestration Over Architecture
This is a critical distinction. While architectural differences between MoE and dense models are real and significant, the observed behavior here was primarily an orchestration problem. It’s easy to get seduced by the sleekness of architectural explanations, especially when dealing with complex systems like LLMs. We want to believe that failures stem from fundamental design choices, not from easily overlooked configuration errors. But the market dynamics of LLM deployment are rarely that clean. It’s about performance tuning, resource allocation, and yes, sometimes, just setting the right budget.
This incident underscores a broader truth: context window management and token limits are not trivial settings. They are active participants in the model’s reasoning process. Overly aggressive capping can lead to what looks like model regression, creating phantom problems that distract from the real issue: insufficient computational headroom.
What does this mean for developers building on these models? It means a renewed focus on diligent testing under realistic conditions. It means treating max_tokens not as a minor parameter, but as a key lever for performance. And it means, perhaps, a healthy skepticism towards sweeping architectural pronouncements when a simpler explanation might be lurking just beneath the surface.
I’m walking this back publicly because the initial assessment was flawed, and that’s okay. The real win here is the discovery, driven by community insight, that sometimes, the densest problems have the simplest solutions.
🧬 Related Insights
- Read more: Gateway API on Kind: Local Testing Without the Hassle
- Read more: Laravel Cron Collisions [Bulletproof Schedules]
Frequently Asked Questions
What was the original problem with Gemma 4?
Initially, the Gemma 4 31B Dense model appeared to be exhibiting false-negative refusals in specific scenarios, unlike its MoE counterpart. This led to speculation about architectural regressions.
What caused the apparent regression?
Subsequent testing revealed that a restrictive max_tokens setting (400) was preventing the dense model’s reasoning layer from completing its output, mimicking regression. Increasing this limit resolved the issue.
Will this affect how I use Gemma 4?
Yes, it highlights the importance of setting an appropriate max_tokens value for your use case to ensure models have sufficient budget to complete their reasoning, particularly for the dense variant.