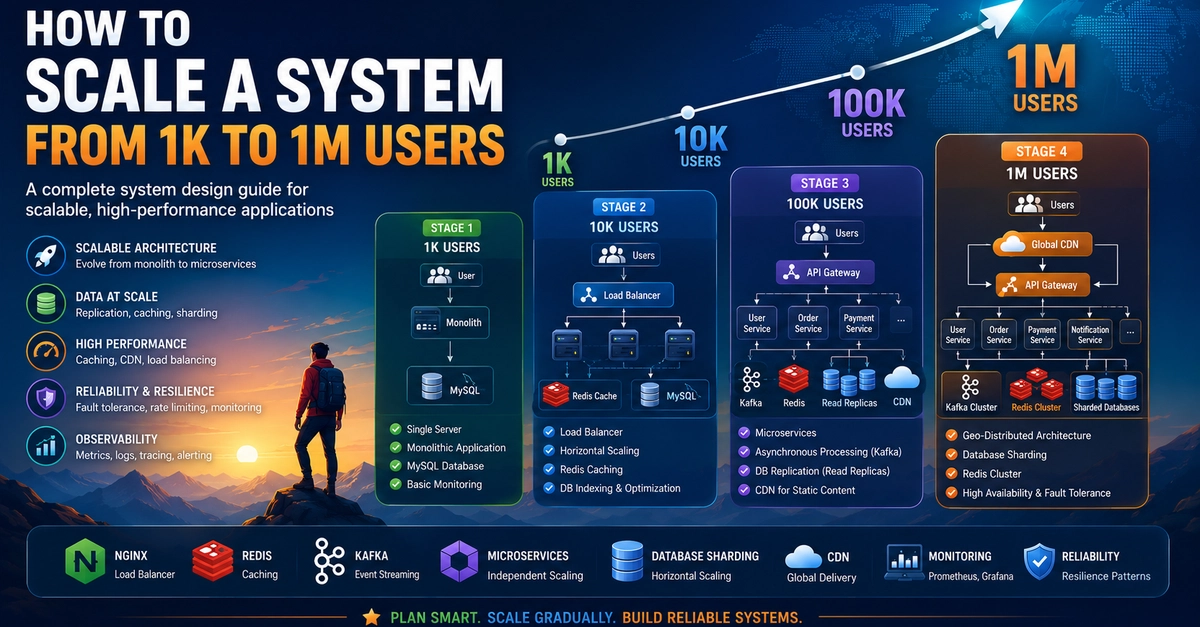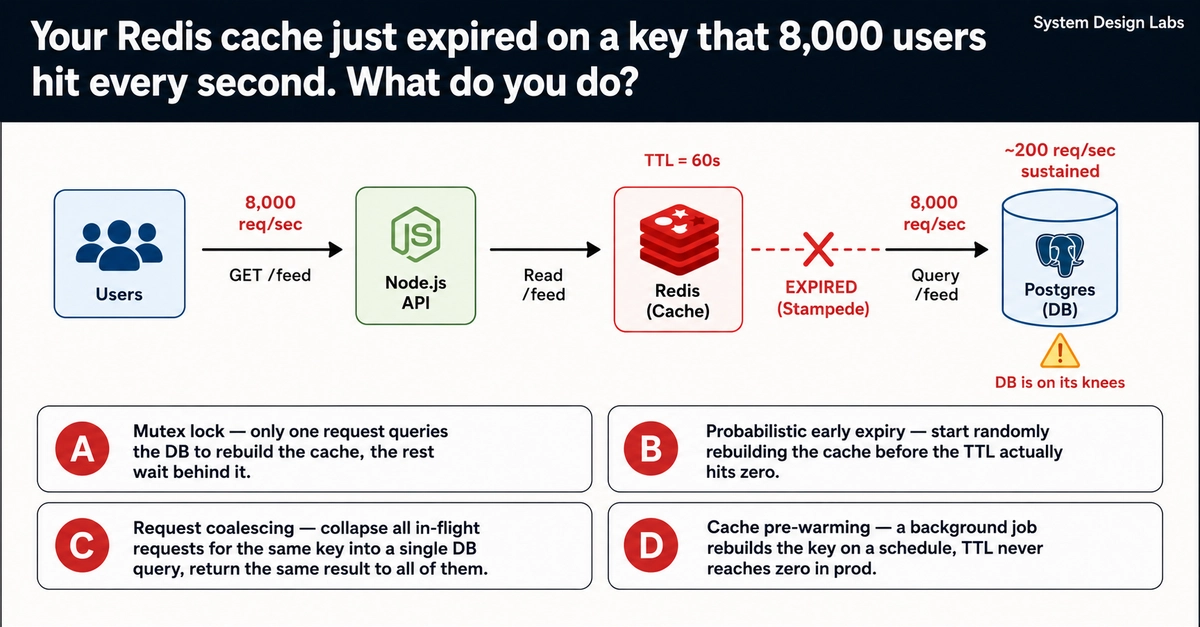
So, your Redis cache just decided to take a permanent vacation, and now 8,000 users per second are all trying to get their data from a database that’s already sweating at 200 requests per second. This isn’t just an inconvenience. This is the thundering herd, a digital stampede that can bring your entire operation to its knees in minutes. And here’s the kicker: the next TTL expiry is looming, ready to unleash the fury all over again.
It’s a classic scenario. A Node.js API, humming along at 8,000 requests per second on its /feed endpoint. A Redis cache, dutifully serving data with a 60-second Time To Live (TTL). And then, the Postgres database, blissfully unaware of the impending doom, chugging along at its comfortable 200 requests per second. Suddenly, that TTL hits zero. Poof. All 8,000 requests, unhindered, go straight for the jugular. Your database, once a bastion of stability, is now gasping for air, minutes from oblivion.
The Options: Band-Aids or Real Fixes?
What’s the immediate survival strategy when your database is on life support? The prompt throws out a few potential lifelines: A) Mutex lock, B) Probabilistic early expiry, C) Request coalescing, and D) Cache pre-warming. All four have seen production use. But only one truly dodges the thundering herd without introducing its own spectacular failure mode under pressure.
The mutex lock sounds elegant, doesn’t it? Let one request do the heavy lifting, fetch the data, rebuild the cache, and let everyone else wait politely. Simple. Except when 8,000 requests are clamoring. That one request becomes a bottleneck of epic proportions. The queue behind it stretches to infinity, and your users are left staring at spinning loaders, wondering if the internet has officially broken. It works for a trickle, not a flood.
Probabilistic early expiry? Sounds like a magician’s trick. Just start refilling the cache randomly before the TTL hits. Cute. But what happens when your random generator decides to be really random? You could end up with a cache that’s never quite ready, or worse, still miss a critical window and trigger the herd anyway. It’s a gamble, and in production, gambles involving your core database are a bad idea.
All four ship in production systems. Only one of them prevents the thundering herd without introducing a new failure mode under load.
Cache pre-warming is the diligent student. A background job, always on schedule, keeping the key fresh. It sounds like the adult in the room. But the trap? It can fail. What if that background job itself is slow? What if it has a bug? What if the schedule is slightly off? A predictable expiry window, even with pre-warming, still leaves a theoretical, albeit small, gap. And when 8,000 requests are poised, even a theoretical gap becomes a gaping chasm.
This leaves request coalescing. It’s not about making one request do all the work, nor is it about hoping for good luck or diligent scheduling. It’s about intelligence. When those 8,000 requests arrive, they’re all asking for the same thing. Coalescing recognizes this. It says, “Hold on a minute, everyone wants the same feed. Let me ask the database once, get the answer, and then hand that same answer back to all 8,000 of you.” It’s efficient. It’s strong. It stops the herd before it even starts.
The Senior Engineer’s Trap
The prompt hints at a “senior-engineer trap.” This is often where theoretical elegance meets harsh reality. Option A, the mutex lock, is a prime candidate. In a low-traffic scenario, it’s perfectly fine. But scale it to 8,000 concurrent requests, and that single lock becomes a crushingly painful bottleneck. It’s a solution that breaks down spectacularly when it’s needed most.
Similarly, probabilistic approaches (B) or even scheduled pre-warming (D) can sound sophisticated. They aim to solve the symptom—the expiry—rather than the root cause: a burst of identical requests hitting an overloaded backend. The truly senior engineer looks for the system-level solution that anticipates and neutralizes the overload gracefully.
Why Does This Matter for Real People?
For the 8,000 users hitting that /feed endpoint, this isn’t an abstract system design problem. It’s the difference between a fluid, instantaneous experience and a frozen screen. It’s the difference between getting their news, updates, or social media posts, and getting nothing but frustration. For the business, it’s downtime, lost revenue, and potentially damaged customer trust. When your systems fail under load, it’s the real people on the other end who pay the price with their patience and engagement.
This is the unglamorous reality of distributed systems. The subtle interactions between caching, databases, and network requests can create cascading failures. It requires not just coding skill, but a deep understanding of how systems behave under stress. It’s about building resilience, not just functionality.
🧬 Related Insights
- Read more: Polpo: Open-Source Runtime That Might Actually Save AI Agents from Infra Hell
- Read more: Laravel Performance: 6 Real-World Lessons
Frequently Asked Questions
What is the “thundering herd” problem in system design?
The thundering herd problem occurs when a distributed cache expires a popular item, causing a massive surge of requests to hit the origin data source simultaneously, potentially overwhelming it.
How does request coalescing solve the cache expiry issue?
Request coalescing groups multiple identical requests for the same resource that arrive at roughly the same time. Instead of querying the database for each request, it makes a single query and returns the same result to all grouped requests, preventing database overload.
Is cache pre-warming a bad idea?
Cache pre-warming isn’t inherently bad; it’s a strategy to proactively populate a cache. However, if not implemented perfectly, it can still leave gaps or become a point of failure, especially when dealing with extremely high request volumes like 8,000 requests per second.